DurIAN: нейросеть генерирует видео и аудио к тексту
29-09-2019, 12:29. Разместил: Swarm
DurIAN — это нейросеть, которая получает на вход текст и одновременно генерирует речь и видео к тексту. Внутри DurIAN авторегрессионная модель, которая соотносит текст с выходной аудиозаписью. DurIAN более устойчива к ошибкам, чем state-of-the-art модель Tacotron.
Ниже представлен пример работы нейросети. Модель сгенерировала фигуру, мимику женщины в 3D и аудиозапись ее разговора.
Ключевой компонент системы — это Duration Informed Attention Network (DurIAN). DurIAN состоит из авторегрессивной модели, которая соотносит текст с характеристиками аудиозаписи с помощью duration model. Этот подход отличается от end-to-end механизма внимания и избегает генерацию артефактов, которые генерируют текущие системы для синтеза речи. DurIAN также может быть использована для генерации выражений лица в высоком разрешении, которые могут быть синхронизированы с сгенерированной речью. При этом модель обучается синхронизировать речь и лицо без параллельных данных для обучения. Чтобы улучшить качество генерации речи, исследователи предлагают модификацию для WaveRNN — Multi-band WaveRNN. Модифицированная модель сокращает общую вычислительную сложность с 9.8 до 3.6 GFLOPS. Multi-band WaveRNN способна генерировать речь в 6 раз быстрее, чем стандартная WaveRNN, на одном CPU.
Также исследователи предлагают подход для контроля за эмоциями в аудио и на видео.
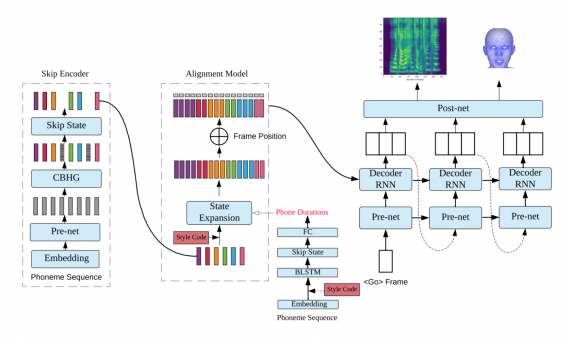
Архитектура модели
Структура модели состоит из 4-х блоков:
- Skip кодировщик, который кодирует фонемы и ударения в тексте;
- Alingment модель соотносит входные фонемы и части аудиозаписи, который отдаются на выходе;
- Авторегрессивный декодировщик генерирует выходные аудиозапись речи и видеозапись лица по частям;
- Post-net предсказывает остатки, которые не предсказал декодировщик
Результаты экспериментов
Чтобы сравнить работу DurIAN и Tacotron 2, исследователи проводят опрос. Участники опроса должны по пятибалльной шкале оценить реалистичность сгенерированных моделями голосов. Ниже видно, что результаты моделей схожи по реалистичности.

Вернуться назад